|
I always wanted to start a series of writeups to study the commute time of the bay area. It would be quite helpful for anyone who plans to move to the bay area to get a glimpse of what is it like to commute in bay area. For those who already work and live here, it may also worth another look at their commute methods.
Of course this would be a huge project, and there are already many different articles on this topic. To narrow it down, I specifically focus on two commute methods: cycling and driving. During non-rush hours, driving is almost always faster than cycling. However, cycling is in general, much less affected by traffic conditions. In heavy traffic condition, cycling could be a faster way to commute. The purpose of the whole project is to compare the commute time between driving and cycling within the South Bay during different times of a Weekday. This is Part I of the project: find out the cycling time within the South Bay. Data Preparation
The first task is to define it and break it into executable action items.
Geographical data
I’d like to plot the area of each Zipcode for Santa Clara County. The boundary of each zip is provided in the shape file that you can download from census.gov. We need to correlate each boundary with the corresponding Zipcode. You can download the Zip code from here.
Since Santa Clara is a big county, some remote Zips are excluded in the analysis.
Data Visualization
Let’s first take a look at each Zip on a map. The zip codes are grouped by each city.
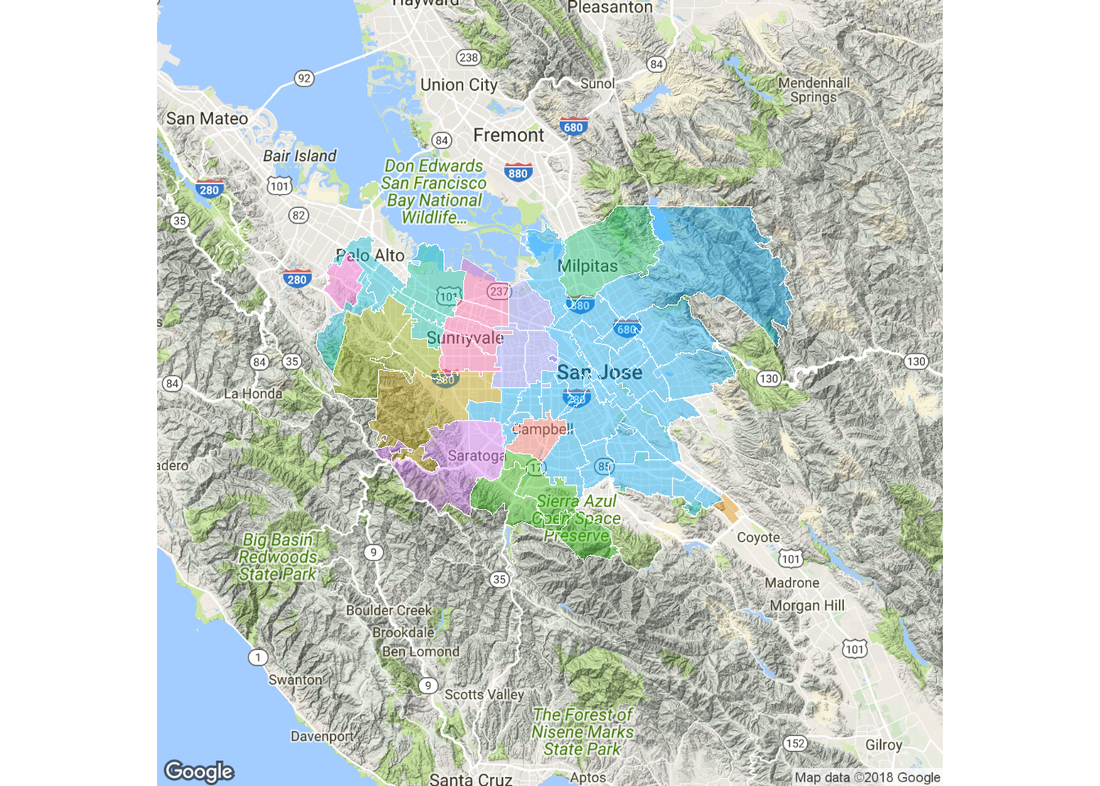
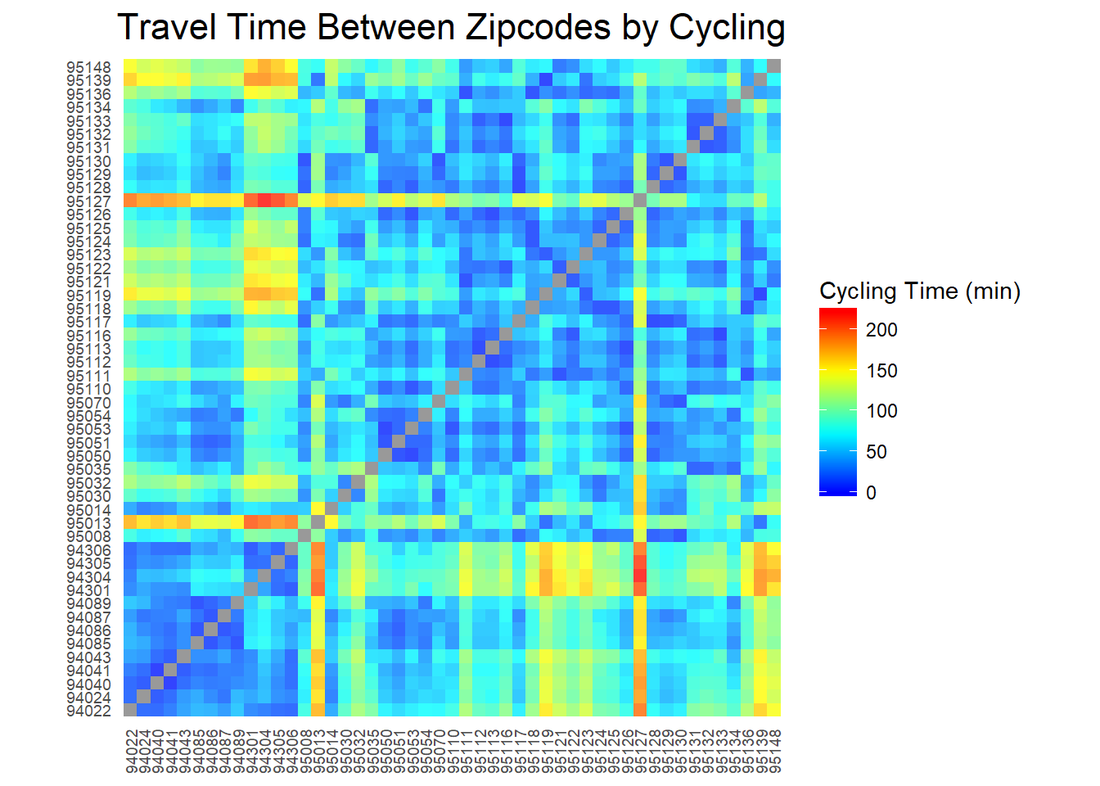
Now, we can create a matrix to show the cycling time between any two zips.
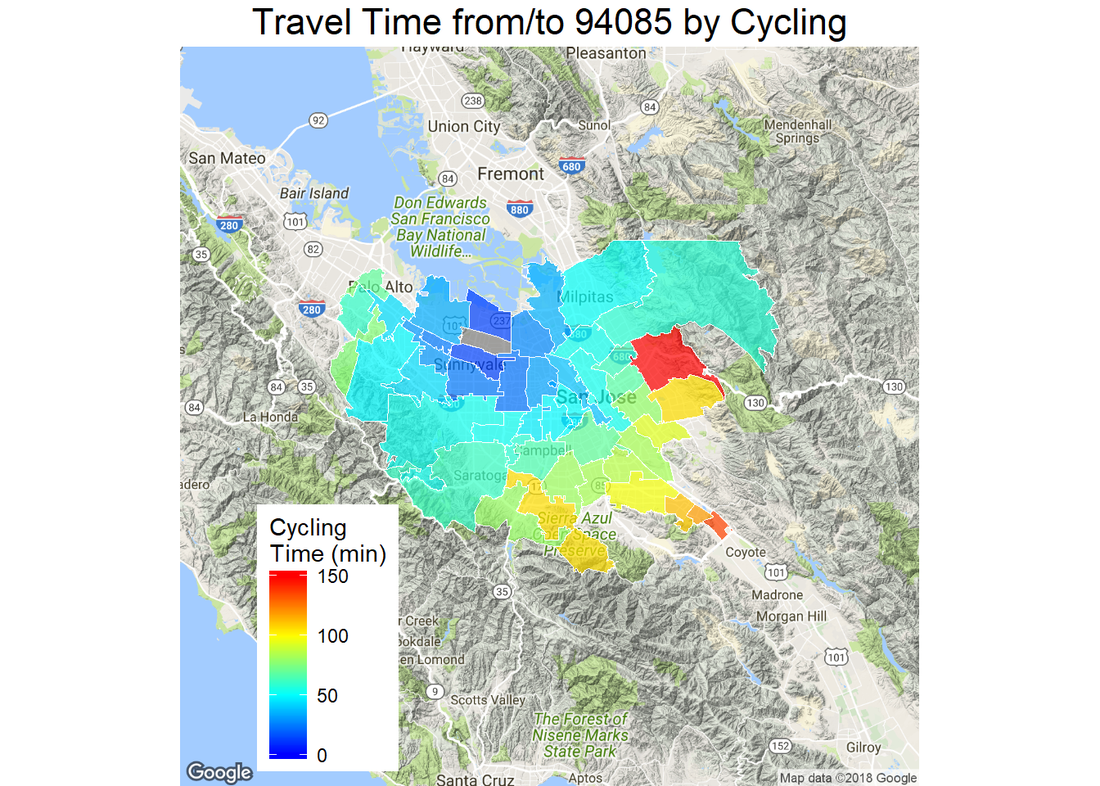
Finally, we can show the commute time from one specific zip 94085 on a map.
Conclusion
The article shows how to plot geographical data on a map and call google map API using the ggmap package. For a big county like Santa Clara, the cycling time between to far away areas could be as long as 3 hours. In Part II of this series, I will exclude any pair of zips whose cycling time is more than 60 mins and compare the driving and cycling time. Stay tuned.
0 Comments
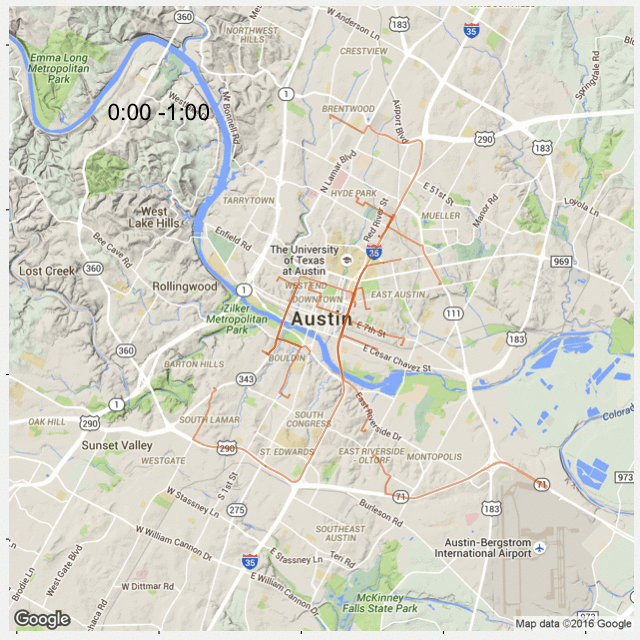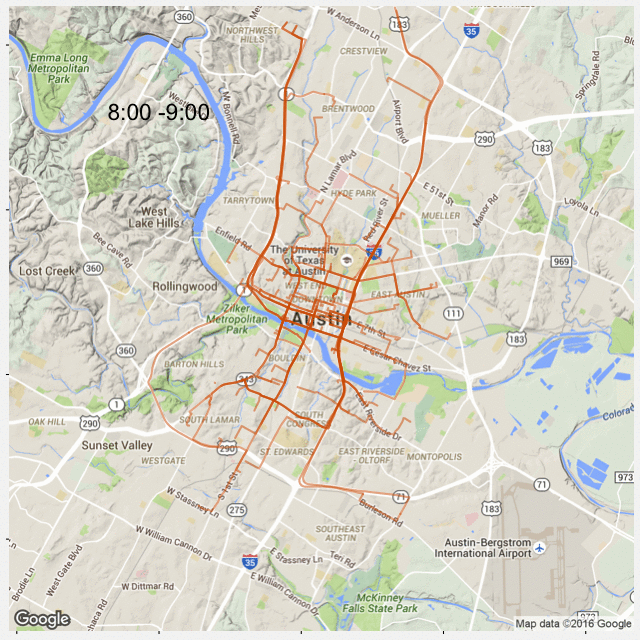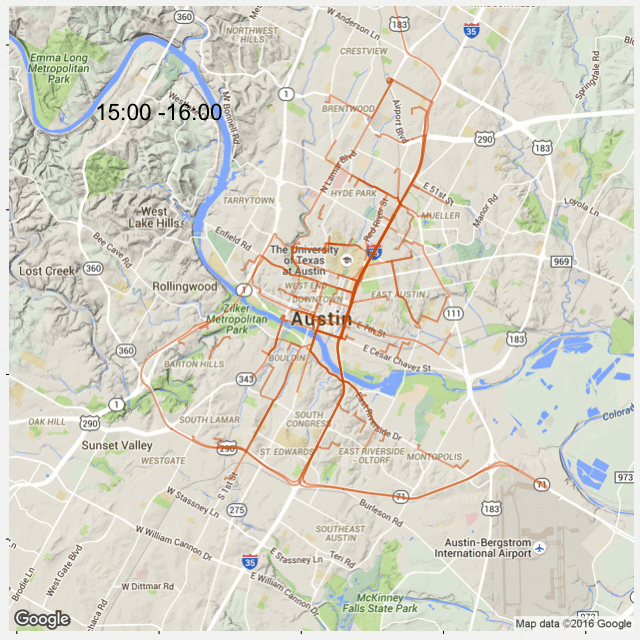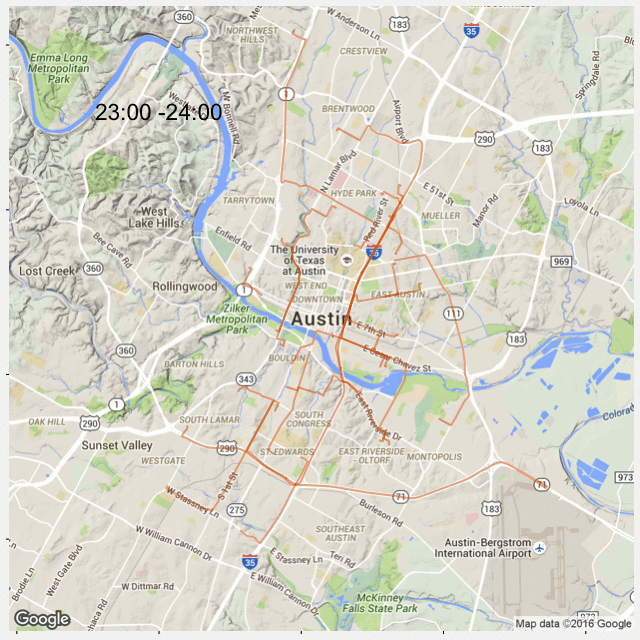
A quick follow-up of my previous post: Most Popular Road in Austin. This time I created 24 plots for each hour during the day so that we can see popular roads at a given time.
Update: using Manhattan distance in k-means
Note the capital 'K' in Kmeans function from the amap package. 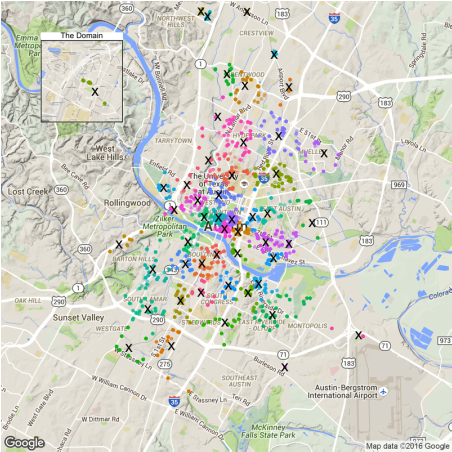
Using 'Manhattan distance' puts more weight to sparsely distributed locations. As a result, we can see more proposed EV locations in remote areas and less in downtown.
Code is published on my github.
Previously, I did some analysis on car2go's location data to find the most popular roads in Austin. But we can do much more. One question I have is: if car2go wants to replace the entire Austin fleet with electric vehicles, where should the charging stations be? Can we use the existing public charging stations? How many more shall we build and where? In this article, I will try to answer them using the data I scraped. If ever one day car2go decides to do so, it should be a more thorough analysis than this one, especially in business domain. However, this could be a good starting point.
Fun fact: Car2go has the only all-EV fleet in San Diego in the whole US. Location data
I'll use the locationI scraped last month. A car will have multiple entries because it is not constantly moving. Those duplicated entries seem redundant at first. However, since charging an EV takes substantially more time than filling the tank, a car staying at one place for a prolonged time makes this place more suitable for a charging station. Therefore, these entries puts more weight in my algorithm later on.
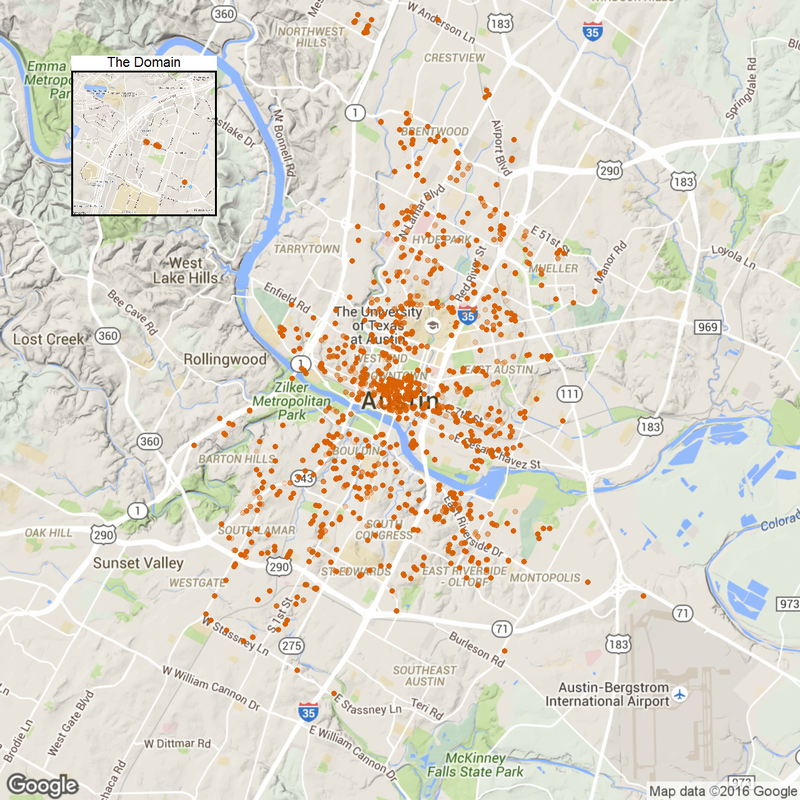
First, let's see those locations. library(ggmap) library(grid) library(dplyr) library(ggplot2) library(broom) time.df <- read.csv('data/1Timedcar2go_week.csv', header = T) #car location plot p1<- ggmap(get_map(location = 'austin', zoom = 12), extent = 'device')+ geom_point(aes(x = Longitude, y = Latitude), data = time.df, alpha = 0.1, color = '#D55E00', size = 4) + theme(legend.position = 'none') p1.2<- ggmap(get_map('domain, austin', zoom = 15), extent = 'device')+ geom_point(aes(x = Longitude, y = Latitude), data = time.df, alpha = 0.1, color = '#D55E00', size = 4) + ggtitle('The Domain')+ theme(legend.position = 'none', plot.title = element_text(size = rel(2)), panel.border = element_rect(colour = "black", fill = NA, size=2)) plot_inset <- function(name, p1, p2){ png(name, width=1280, height=1280) grid.newpage() v1<-viewport(width = 1, height = 1, x = 0.5, y = 0.5) #plot area for the main map v2<-viewport(width = 0.2, height = 0.2, x = 0.18, y = 0.83) #plot area for the inset map print(p1,vp=v1) print(p2,vp=v2) dev.off() } plot_inset('1.png', p1, p1.2)
Note those remote home areas: the domain, far west and the parking spot near airport.
Finding optimal location for charging stations
To locate optimal charging stations, we need to minimize the distance that car2go staff have to move the car from where it is returned to the station. One method immediately coming to mind is K-means. It does exactly what we need to find those locations (or centroids). So the next question is: how many charging stations? Can we use the data to determine the number? Let's plot the within-group sum of square.
set.seed(18) wss <- data.frame(clusterNo = seq(1,50), wss = rep(0, 50)) for (i in 1:50){ clust.k <-time.df %>% select(Longitude, Latitude) %>% kmeans(i, iter.max=500) wss$wss[i] <- clust.k$tot.withinss } p2 <- ggplot(wss)+geom_point(aes(clusterNo, wss), size = 4, shape = 1, color='#009E73')+ xlab('No. of Centroids') + ylab('WSS') + theme_bw(18) png('2.png', width=640, height=480) print(p2) dev.off() 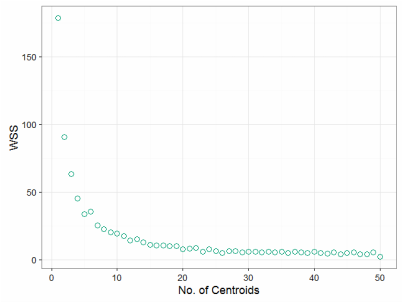
So it seems after 10, the overall WSS reduction is not significant wrt increasing no. of centroids. But is this the optimal number? It seems too few. We have to consider more aspects: cost of a new charging station, cost of moving the vehicles per unit distance, max range of a car, or even towing expence. All these requires more data and a business mind. For the sake of this article, I will assume building a charging station is relatively cheap and top priority is customer convenience. So let's take 50 charging stations.
#50 charging station clust <- time.df %>% select(Longitude, Latitude) %>% kmeans(50, iter.max=500) p3<- ggmap(get_map(location = 'austin', zoom = 12), extent = 'device')+ geom_point(data=augment(clust, time.df), aes(x = Longitude, y = Latitude, color = .cluster), alpha =0.1, size = 4) + geom_point(aes(Longitude, Latitude), data = data.frame(clust$centers), size = 15, shape = 'x') + theme(legend.position = 'none') p3.2<- ggmap(get_map('domain, austin', zoom = 15), extent = 'device')+ geom_point(data=augment(clust, time.df), aes(x = Longitude, y = Latitude, color = .cluster), alpha =0.1, size = 4) + geom_point(aes(Longitude, Latitude), data = data.frame(clust$centers), size = 15, shape = 'x') + ggtitle('The Domain')+ theme(legend.position = 'none', plot.title = element_text(size = rel(2)), panel.border = element_rect(colour = "black", fill = NA, size=2)) plot_inset('3.png', p3, p3.2) 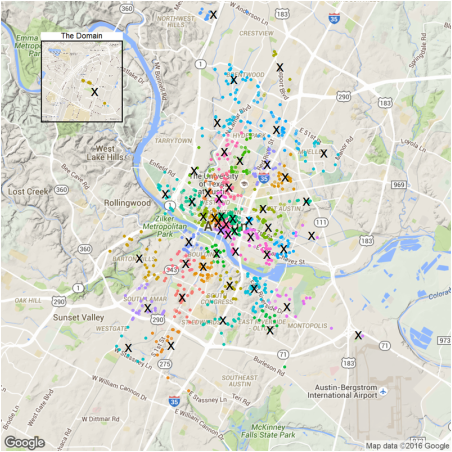
So the crosses in the figure are proposed charging stations. The algorithm suggests we deploy the station at each of those remote home areas: the domain, far west and the parking spot near airport. More stations should be deployed in downtown as expected.
Using existing public charging stations
For those locations, can we use existing charging stations in Ausin? I downloaded ev station data from here: http://www.afdc.energy.gov/data_download/. Now let's plot proposed (X) and existing stations (E) together.
station.df <- read.csv('data/charging_stations (Feb 20 2016).csv', header = T) station.austin = station.df%>%dplyr::filter(City=='Austin') p4<- ggmap(get_map(location = 'austin', zoom = 12), extent = 'device')+ geom_point(aes(Longitude, Latitude), data = data.frame(clust$centers), size = 15, shape = 'x') + geom_point(aes(x = Longitude, y = Latitude), data = station.austin, size = 14, shape = 'E', color = '#009E73') + theme(legend.position = 'none') p4.2<- ggmap(get_map('domain, austin', zoom = 15), extent = 'device')+ geom_point(aes(Longitude, Latitude), data = data.frame(clust$centers), size = 15, shape = 'x') + geom_point(aes(x = Longitude, y = Latitude), data = station.austin, size = 14, shape = 'E', color = '#009E73') + ggtitle('The Domain')+ theme(legend.position = 'none', plot.title = element_text(size = rel(2)), panel.border = element_rect(colour = "black", fill = NA, size=2)) plot_inset('4.png', p4, p4.2) 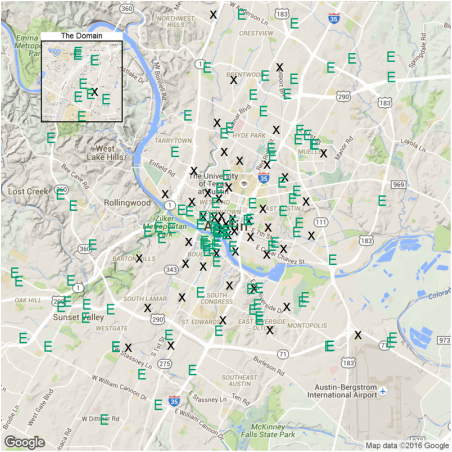
Again, downtown is well covered. But residential areas like Barton hills and South Lamar are not. The reason is that public EV stations are often built in places of interest (e.g. malls) while car2go parking rules require the cars to park on street meters. If I have to park at a mall, I need to pay the entire duration. So given this fact, it is not suprising that additional charging stations are needed.
The criteria for a new station is that no existing station is within 0.5 miles of the proposed station. station.dist <- mutate(data.frame(clust$centers), distToExist= 0) for (i in 1:nrow(station.dist)){ # In the area of Austin, one dgree in Latitude is 69.1 miles, # while one degree in Longitude is 59.7 miles d <- sqrt(((station.austin$Latitude-station.dist$Latitude[i])*69.1)**2 +((station.austin$Longitude-station.dist$Longitude[i])*59.7)**2) station.dist$distToExist[i] <- min(d) } p5 <-ggmap(get_map(location = 'austin', zoom = 12), extent = 'device')+ geom_point(aes(Longitude, Latitude, color = -sign(distToExist-0.5)), data = station.dist, size = 15, shape = 'x') + geom_point(aes(x = Longitude, y = Latitude), data = station.austin, size = 14, shape = 'E', color = '#009E73') + theme(legend.position = 'none') p5.2<- ggmap(get_map('domain, austin', zoom = 15), extent = 'device')+ geom_point(aes(Longitude, Latitude, color = -sign(distToExist-0.5)), data = station.dist, size = 15, shape = 'x') + geom_point(aes(x = Longitude, y = Latitude), data = station.austin, size = 14, shape = 'E', color = '#009E73') + ggtitle('The Domain')+ theme(legend.position = 'none', plot.title = element_text(size = rel(2)), panel.border = element_rect(colour = "black", fill = NA, size=2)) plot_inset('5.png', p5, p5.2) 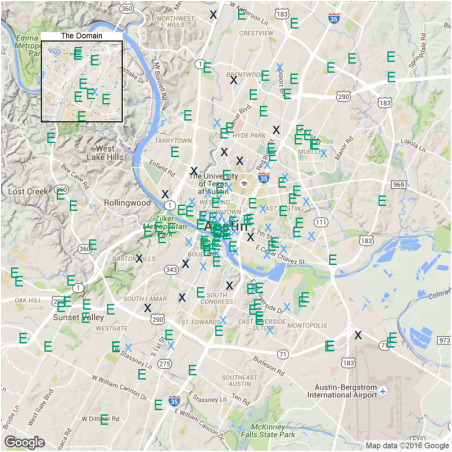
The light-blue crosses represent a station very close to existing ones and dark-blue crosses are new one to be built. There are 14 in total.
Conclusion
OK there you have it. I just used the k-means method to propose new charging stations if car2to decides to deploy an all-EV fleet in Austin. There are 14 locations that require new charging stations. Most of these locations are residential areas far from downtown, where the EV infastructure is lacking.
Back to R script, k-means is really easy to implement. The harder part is to connect the data with business insights. IntroductionIn my last post, we walked through the construction of a two-layer neural network and used it to classify the MNIST dataset. Today, I will show how we can build a logistic regression model from scratch (spoiler: it’s much simpler than a neural network). Linear and logistic regression are probably the simplest yet useful models in a lot of fields. They are fast to implement and also easy to interpret. In this post, I will first talk about the basics of logistic regression, followed by model construction and training on my NBA shot log dataset, then I will try to interpret the model through statistical inference. Finally, I will compare it with the built-in Logistic regressionLogistic regression is a generalized linear model, with a binominal distribution and logit link function. The outcome \(Y\) is either 1 or 0. What we are interested in is the expected values of \(Y\), \(E(Y)\). In this case, they can also be thought as probability of getting 1, \(p\). However, because \(p\) is bounded between 0 and 1, it’s hard to implement the method similar to what we did for linear regression. So instead of predicting \(p\) directly, we predict the log of odds (logit), which takes values from \(-\infty\) to \(\infty\). Now the function is: \(\log(\frac{p}{1-p})=\theta_0 + \theta_1x_1 + \theta_2x_2 + ...\), let’s denote the RHS as \(x\cdot\theta\). Next the task is to find \(\theta\). In logistic regresion, the cost function is defined as: \(J=-\frac{1}{m}\sum_{i=1}^m(y^{(i)}\log(h(x^{(i)}))+(1-y^{(i)})\log(1-h(x^{(i)})))\), where \(h(x)=\frac{1}{1+e^{-x\cdot\theta}}\) is the sigmoid function, inverse of logit function. We can use gradient descent to find the optimal \(\theta\) that minimizes \(J\). So this is basically the process to construct the model. It is actually simpler than you think when you starting coding. Model construction in RNow let’s build our logistic regression. First I will define some useful functions. Note
Here comes the logistic regression fuction, which takes training dataframe X, and label y as function input. It returns a column vector which stores the coefficients in theta. One thing to pay attention to is that the input X usually doesn’t have a bias term, the leading column vector of 1, so I added this column in the function.
Training with NBA shot log datasetNow let’s train our model with the NBA shot log dataset. Specifically, I am interested in how will shot clock, shot distance and defender distance affect shooting performance. Naively, we would think more time remaining in shot clock, shorter distance to basket, farther to defender will all increase the probability of a field goal. Shortly, we will see whether we can statistically prove that.
How do we interpret the model?
Now, look at the signs of the coefficients, we can conclude that increase in SHOT_CLOCK, CLOSE_DEF_DIST and decrease in SHOT_DIST will all have positive impact in FG%. Next, let’s compare our self-built model with the
We did a pretty good job as the coefficient are almost identical to 3rd decimal place. Prediction function and the Expected FG%Finally, I will write a prediction function that will output the probability of getting 1 in a logistic regression.
Generate a new data grid to see how FG% changes with predictors.
Visulize the impactShot clock seems to have the least impact, so I will exclude that in this plot.
Indeed, wide open shots in the paint have the highest probability and contested long 3s have the lowest. This plot conveys very similar information as the one I did in my shiny app. However, doing regression smoothens things out (regression to mean?) and losses some important features. For example, the predictions of extreme cases (shot distance < 5ft or > 35ft) are all less drastic than what the reality is. Adding higher order terms will be a way to improve.
ConclusionThere you have it, it is not that hard for ourselves to build a regression model from scratch (as we also demonstrated in neural network). If you follow this post, hopefully by now, you have a better understanding of logistic regression. One last note, although logistic regression is often said to be a classifier, it can also be used for regression (to find the probability). Introduction
Image classification is one important field in Computer Vision, not only because so many applications are associated with it, but also a lot of Computer Vision problems can be effectively reduced to image classification. The state of art tool in image classification is Convolutional Neural Network (CNN). In this article, I am going to write a simple Neural Network with 2 layers (fully connected). First, I will train it to classify a set of 4-class 2D data and visualize the decision boundary. Second, I am going to train my NN with the famous MNIST data (you can download it here: https://www.kaggle.com/c/digit-recognizer/download/train.csv) and see its performance. The first part is inspired by CS 231n course offered by Stanford: http://cs231n.github.io/, which is taught in Python.
Data set generation
First, let’s create a spiral dataset with 4 classes and 200 examples each.
library(ggplot2) library(caret) N <- 200 # number of points per class D <- 2 # dimensionality K <- 4 # number of classes X <- data.frame() # data matrix (each row = single example) y <- data.frame() # class labels set.seed(308) for (j in (1:K)){ r <- seq(0.05,1,length.out = N) # radius t <- seq((j-1)*4.7,j*4.7, length.out = N) + rnorm(N, sd = 0.3) # theta Xtemp <- data.frame(x =r*sin(t) , y = r*cos(t)) ytemp <- data.frame(matrix(j, N, 1)) X <- rbind(X, Xtemp) y <- rbind(y, ytemp) } data <- cbind(X,y) colnames(data) <- c(colnames(X), 'label')
X, y are 800 by 2 and 800 by 1 data frames respectively, and they are created in a way such that a linear classifier cannot separate them. Since the data is 2D, we can easily visualize it on a plot. They are roughly evenly spaced and indeed a line is not a good decision boundary.
x_min <- min(X[,1])-0.2; x_max <- max(X[,1])+0.2 y_min <- min(X[,2])-0.2; y_max <- max(X[,2])+0.2 # lets visualize the data: ggplot(data) + geom_point(aes(x=x, y=y, color = as.character(label)), size = 2) + theme_bw(base_size = 15) + xlim(x_min, x_max) + ylim(y_min, y_max) + ggtitle('Spiral Data Visulization') + coord_fixed(ratio = 0.8) + theme(axis.ticks=element_blank(), panel.grid.major = element_blank(), panel.grid.minor = element_blank(), axis.text=element_blank(), axis.title=element_blank(), legend.position = 'none') 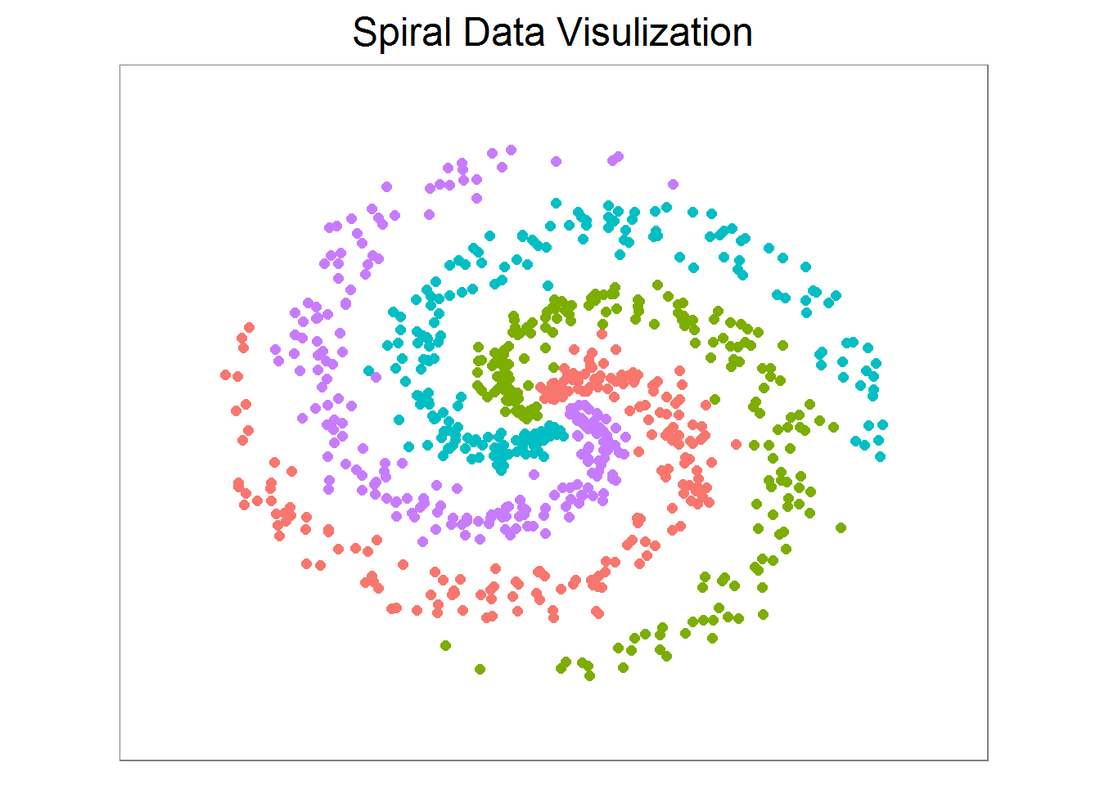
Neural network construction
Now, let’s construct a NN with 2 layers. But before that, we need to convert X into a matrix (for matrix operation later on). For labels in y, a new matrix Y (800 by 4) is created such that for each example (each row in Y), the entry with index==label is 1 (and 0 otherwise).
Next, let’s build a function ‘nnet’ that takes two matrices X and Y and returns a list of 4 with W, b and W2, b2 (weight and bias for each layer). I can specify step_size (learning rate) and regularization strength (reg, sometimes symbolized as lambda).
For the choice of activation and loss (cost) function, ReLU and softmax are selected respectively. If you have taken the ML class by Andrew Ng (strongly recommended), sigmoid and logistic cost function are chosen in the course notes and assignment. They look slightly different, but can be implemented fairly easily just by modifying the following code. Also note that the implementation below uses vectorized operation that may seem hard to follow. If so, you can write down dimensions of each matrix and check multiplications and so on. By doing so, you also know what’s under the hood for a neural network. # %*% dot product, * element wise product nnet <- function(X, Y, step_size = 0.5, reg = 0.001, h = 10, niteration){ # get dim of input N <- nrow(X) # number of examples K <- ncol(Y) # number of classes D <- ncol(X) # dimensionality # initialize parameters randomly W <- 0.01 * matrix(rnorm(D*h), nrow = D) b <- matrix(0, nrow = 1, ncol = h) W2 <- 0.01 * matrix(rnorm(h*K), nrow = h) b2 <- matrix(0, nrow = 1, ncol = K) # gradient descent loop to update weight and bias for (i in 0:niteration){ # hidden layer, ReLU activation hidden_layer <- pmax(0, X%*% W + matrix(rep(b,N), nrow = N, byrow = T)) hidden_layer <- matrix(hidden_layer, nrow = N) # class score scores <- hidden_layer%*%W2 + matrix(rep(b2,N), nrow = N, byrow = T) # compute and normalize class probabilities exp_scores <- exp(scores) probs <- exp_scores / rowSums(exp_scores) # compute the loss: sofmax and regularization corect_logprobs <- -log(probs) data_loss <- sum(corect_logprobs*Y)/N reg_loss <- 0.5*reg*sum(W*W) + 0.5*reg*sum(W2*W2) loss <- data_loss + reg_loss # check progress if (i%%1000 == 0 | i == niteration){ print(paste("iteration", i,': loss', loss))} # compute the gradient on scores dscores <- probs-Y dscores <- dscores/N # backpropate the gradient to the parameters dW2 <- t(hidden_layer)%*%dscores db2 <- colSums(dscores) # next backprop into hidden layer dhidden <- dscores%*%t(W2) # backprop the ReLU non-linearity dhidden[hidden_layer <= 0] <- 0 # finally into W,b dW <- t(X)%*%dhidden db <- colSums(dhidden) # add regularization gradient contribution dW2 <- dW2 + reg *W2 dW <- dW + reg *W # update parameter W <- W-step_size*dW b <- b-step_size*db W2 <- W2-step_size*dW2 b2 <- b2-step_size*db2 } return(list(W, b, W2, b2)) } Prediction function and model training
Next, create a prediction function, which takes X (same col as training X but may have different rows) and layer parameters as input. The output is the column index of max score in each row. In this example, the output is simply the label of each class. Now we can print out the training accuracy.
nnetPred <- function(X, para = list()){ W <- para[[1]] b <- para[[2]] W2 <- para[[3]] b2 <- para[[4]] N <- nrow(X) hidden_layer <- pmax(0, X%*% W + matrix(rep(b,N), nrow = N, byrow = T)) hidden_layer <- matrix(hidden_layer, nrow = N) scores <- hidden_layer%*%W2 + matrix(rep(b2,N), nrow = N, byrow = T) predicted_class <- apply(scores, 1, which.max) return(predicted_class) } nnet.model <- nnet(X, Y, step_size = 0.4,reg = 0.0002, h=50, niteration = 6000) ## [1] "iteration 0 : loss 1.38628868932674" ## [1] "iteration 1000 : loss 0.967921639616882" ## [1] "iteration 2000 : loss 0.448881467342854" ## [1] "iteration 3000 : loss 0.293036646147359" ## [1] "iteration 4000 : loss 0.244380009480792" ## [1] "iteration 5000 : loss 0.225211501612035" ## [1] "iteration 6000 : loss 0.218468573259166"
## [1] "training accuracy: 0.96375"
Decision boundary
Next, let’s plot the decision boundary. We can also use the caret package and train different classifiers with the data and visualize the decision boundaries. It is very interesting to see how different algorithms make decisions. This is going to be another post.
# plot the resulting classifier hs <- 0.01 grid <- as.matrix(expand.grid(seq(x_min, x_max, by = hs), seq(y_min, y_max, by =hs))) Z <- nnetPred(grid, nnet.model) ggplot()+ geom_tile(aes(x = grid[,1],y = grid[,2],fill=as.character(Z)), alpha = 0.3, show.legend = F)+ geom_point(data = data, aes(x=x, y=y, color = as.character(label)), size = 2) + theme_bw(base_size = 15) + ggtitle('Neural Network Decision Boundary') + coord_fixed(ratio = 0.8) + theme(axis.ticks=element_blank(), panel.grid.major = element_blank(), panel.grid.minor = element_blank(), axis.text=element_blank(), axis.title=element_blank(), legend.position = 'none') 
MNIST data and preprocessing
The famous MNIST (“Modified National Institute of Standards and Technology”) dataset is a classic within the Machine Learning community that has been extensively studied. It is a collection of handwritten digits that are decomposed into a csv file, with each row representing one example, and the column values are grey scale from 0-255 of each pixel. First, let’s display an image.
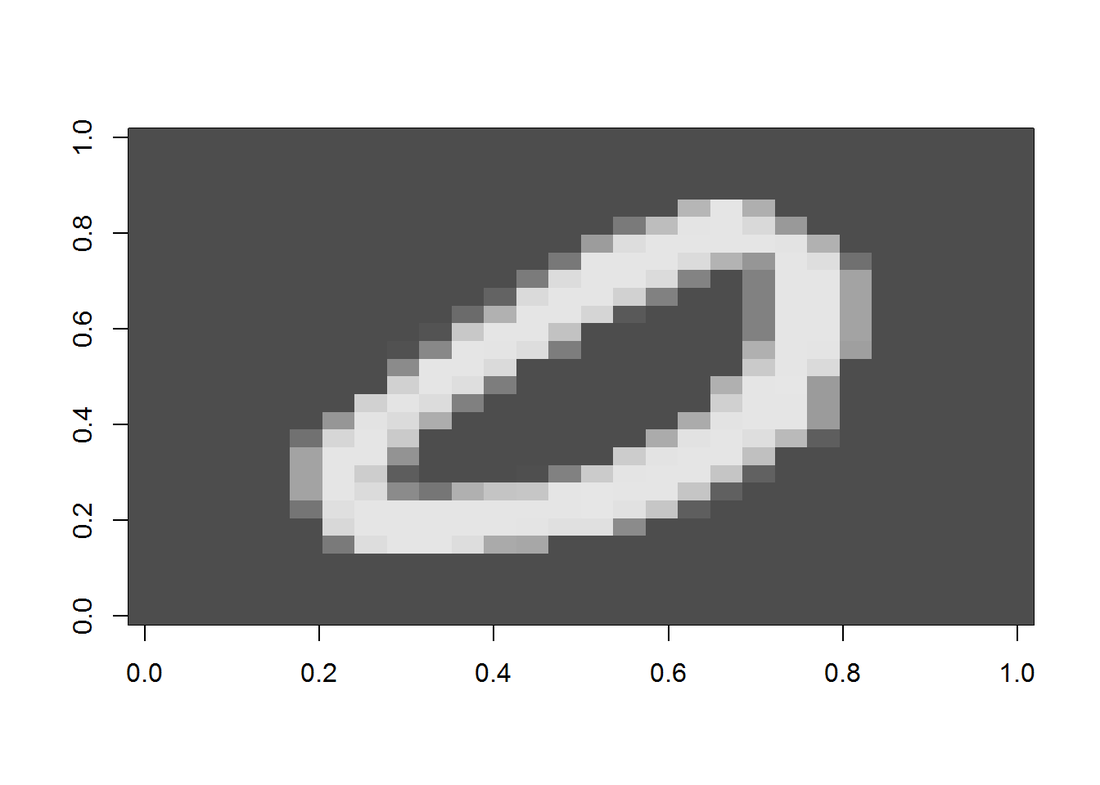
Now, let’s preprocess the data by removing near zero variance columns and scaling by max(X). The data is also splitted into two for cross validation. Once again, we need to creat a Y matrix with dimension N by K. This time the non-zero index in each row is offset by 1: label 0 will have entry 1 at index 1, label 1 will have entry 1 at index 2, and so on. In the end, we need to convert it back. (Another way is put 0 at index 10 and no offset for the rest labels.)
nzv <- nearZeroVar(train) nzv.nolabel <- nzv-1 inTrain <- createDataPartition(y=train$label, p=0.7, list=F) training <- train[inTrain, ] CV <- train[-inTrain, ] X <- as.matrix(training[, -1]) # data matrix (each row = single example) N <- nrow(X) # number of examples y <- training[, 1] # class labels K <- length(unique(y)) # number of classes X.proc <- X[, -nzv.nolabel]/max(X) # scale D <- ncol(X.proc) # dimensionality Xcv <- as.matrix(CV[, -1]) # data matrix (each row = single example) ycv <- CV[, 1] # class labels Xcv.proc <- Xcv[, -nzv.nolabel]/max(X) # scale CV data Y <- matrix(0, N, K) for (i in 1:N){ Y[i, y[i]+1] <- 1 } Model training and CV accuracy
Now we can train the model with the training set. Note even after removing nzv columns, the data is still huge, so it may take a while for result to converge. Here I am only training the model for 3500 interations. You can vary the iterations, learning rate and regularization strength and plot the learning curve for optimal fitting.
nnet.mnist <- nnet(X.proc, Y, step_size = 0.3, reg = 0.0001, niteration = 3500) ## [1] "iteration 0 : loss 2.30265553844748" ## [1] "iteration 1000 : loss 0.303718250939774" ## [1] "iteration 2000 : loss 0.271780096710725" ## [1] "iteration 3000 : loss 0.252415244824614" ## [1] "iteration 3500 : loss 0.250350279456443"
## [1] "training set accuracy: 0.93089140563888"
## [1] "CV accuracy: 0.912360085734699"
Prediction of a random image
Finally, let’s randomly select an image and predict the label.
## [1] "The predicted digit is: 3"
displayDigit(Xtest) 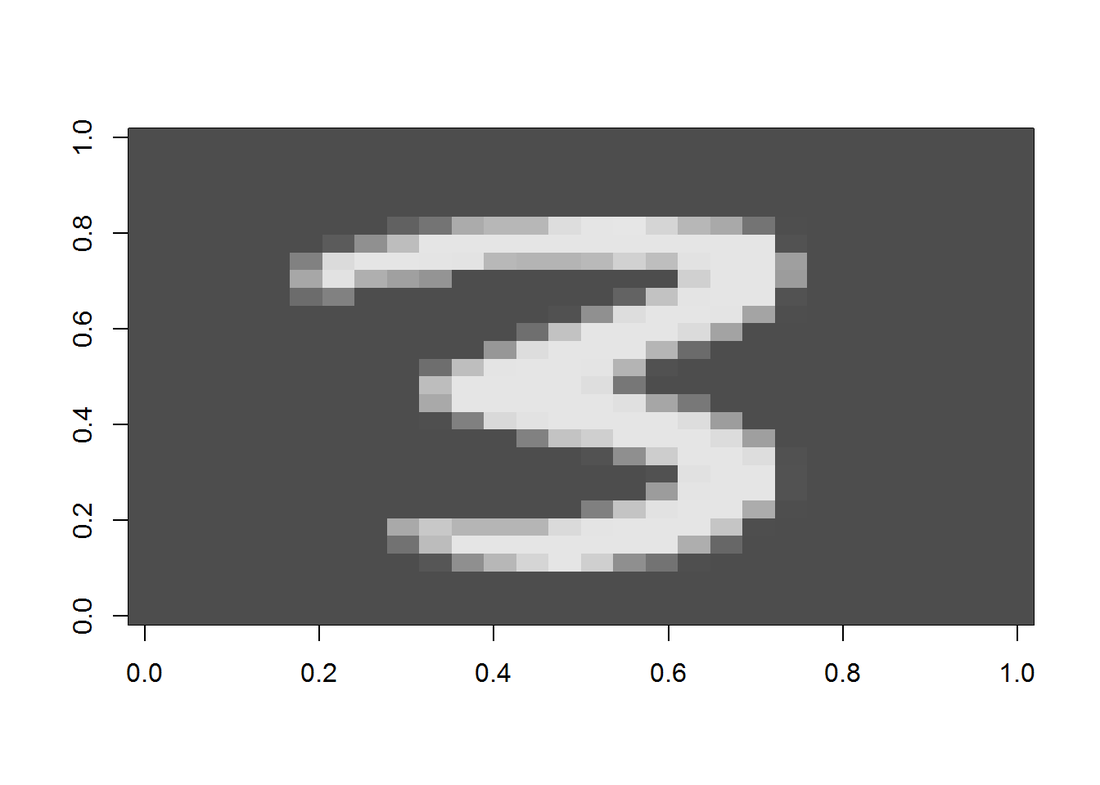
Conclusion
It is rare nowadays for us to write our own machine learning algorithm from ground up. There are tons of packages available and they most likey outperform this one. However, by doing so, I really gained a deep understanding how neural network works. And at the end of the day, seeing your own model produces a pretty good accuracy is a huge satisfaction.
Update: It appears to me that nba.com has removed the access to shot log data as of 02/10/2016. The scraped data is still available on my github.
IntroductionShiny app is a new way to present data interactively. Unlike methods like D3, shiny performs complex calculation in real time. As a result, shiny app is more powerful and versatile. However, this also means one cannot simply embed an interactive shiny app in an html document. It needs to be hosted on a shiny server. I rented one on digital ocean, and here is my shiny app for NBA stat in previous post. You may open that article and play with the app while reading this one. Note the code in this markdown file does not evaluate. app.RA shiny app has two main component: UI for app layout and server for computation and output. These two are linked by a shiny app object app.R shown below as an example. Libraries, data and functions are loaded first (make sure data is loaded globally). You can also load data locally in server.R. In the example below, I used navbar page layout with name ‘NBA’. It has one tab ‘Shooting Statistics’. It is also easy to included multiple tabs by adding
Define UII choose a sidebar layout comprised of a sidebar and a main panel. Also bear in mind that the layout may be different depending on the size of your browser. The side bar is mainly for user input. For example, a user can choose different NBA seasons and different players. Because player list is different for each season, the app will decide which list to display based on which season the user has chosen. To realize ths function, I use
Notice the first argument of each Computation in server.RSo now comes to the main contributor behind the scene, the server file. Basically, what needs to be updated is all in this file. Like I mentioned before, it is also responsible for one of the UI components
The real output is rendered every time there is an update from user. The first plot shows the FG percentage at different location with different defender distance. The semi-transparent bars are for league average and the numbers at the top of the bar is “FG made/FG Attempt”. The update action in this plot happens in
In the second tab, we return two pie charts.
Finally, we can evaluate offensive performance of a player in the following plot. The analysis is in my previous post. The table is pre-constructed and loaded in the app. You can select a play to see his performance highlited in red with player’s name shown on the plot.
ConclusionAs you can see, it is quite easy to construct a shny app once you have the data. It is especially efficient if you need to show lots of similar data inside a large data set. In this scenario, shiny lets you construct one plot and you can simply change the input to ask shiny to update the plot. IMO, this is the biggest advantage of shiny to other interative visualization methods. Update: It appears to me that nba.com has removed the access to shot log data as of 02/10/2016. The scraped data is still available on my github. It is hard to convincingly evaluate a player's contribution to team offense, given so many factors involved, both objective and subjective. I took a shot at this problem by analyzing what kind of shot a player takes and how's that compared with league average. The result, as we shall see later, is quite inline with what we would expect. This is part I of the 2-part series. Part I mainly focuses on the analysis, while part II on building the Shiny app, with a potential part III for case studies. tl;dr: here is my final web app for this project. You can right click the plot and download it to create your own case study. Enjoy! Data used in the analysisI scraped each player's shot log from stat.nba.com for the last two seasons. The code for this task can be found in my previous post. The data consists of almost 300k shots in total and 400+ players each season. For each shot, it provides metrics like shot distance, shot clock, defender distance and the outcome of the shot etc. In this analysis, I will choose the two most important ones, shot distance and defender distance. They comprise an essential portion of a player's shot selection and have fundamental influence on the outcome of the shot. Analysis using RAfter the data is ready-tidy, the fun analysis begins with breaking down shot distance and defender distance. I divide shot distance into 8 catogories: 0-5 ft all the way up to 35+ with 5 ft interval and defender distance into 4: 0-2 ft up to 6+ with 2 ft interval. One for loop for different defender distance nested inside another for loop for shot distance. The following function takes a single data.frame argument in the shot log format and returns the FG%, total FGA, total FGM Pts and 2pt/total for each shot distance and defender distance. So depending on the input data.frame, we can get either the league average or the data for an individual player. I used chaining to simplify the code and it worked really well. I tried to use ddply(), it worked in the main script, however not inside a function due to some scoping bug. Code Editor
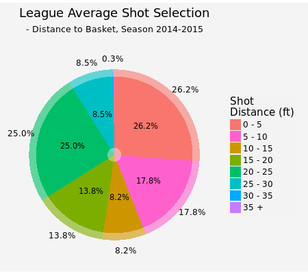
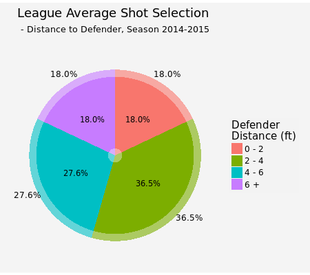
League averageOnce the function is constructed, we can first look at the league average shooting performance. This plot has two parts: the semi-transparent bar for league average and solid color for the player of interest, in this case league average as well (I kept both for consitensy with later plots for individual players). 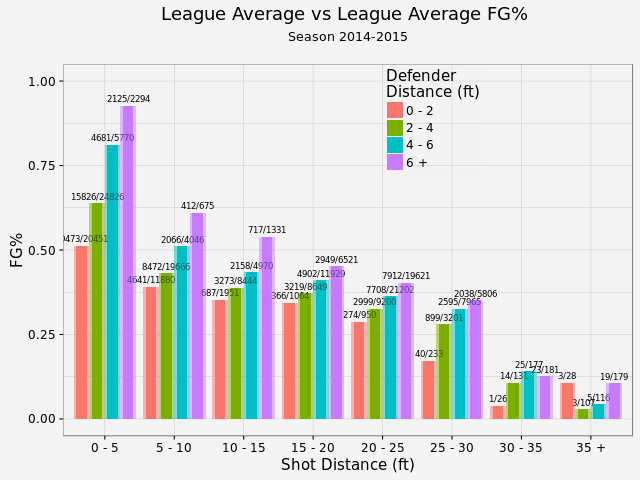 There is a clear trend that the closer to the basket, the better FG%. For the same range of shot distance, the farther the defender is, the better FG%. We've got a large enough sample size that we actually statistically proved it (except shot distance > 30 ft, where the sample size is limited)! As for shot selection, about quarter of the total shots are inside 5 ft or between 20-25 ft (this is a choice of compromise. NBA has a varying 3pts distance from 22 to 24 ft, so it is difficult to use shot distance for 2pt/3pt indication. However, about 75% of the shots between 20-25 ft are 3 pointers. So this range is a fairly good indicator for close 3 pointers). These two types shots are easy shots, or easy shots-with-good-return. 8.5% are long 3 pointers and less than 1% total for desperation shots (30-35 ft and 35+ ft). On the other hand, 46% of the shots are open (and 18% are wide open). Another 18% are closely contested while 37% are within normal defender distance 2-4 ft. By displaying an individual player's shot selection, we can see whether this player likes 3 pointers, prefers open shots and etc.
Speaking of season to season variation, there is very little difference between the last two seasons (although this seanson I only gathered about 1/3 of the shots as last season). You can take a look by yourself. Player value added to team offenseNow let me try to answer the question I posted at the beginning of this article. The way I look at it is that I trust a player's shot selection under circumstances on the court (after all, too many bad shots would get you benched). However, the player should be responsible for the shot choice he took: if he ouperformes league average on a contested long 3, he has added positive value to team offense. If the player misses a wide open lay up, he has added a much negative value because wide open lay ups have very high points expectation. With that in mind, here is my take on player value: 1, obtain the league average FG% (as in previous section) 2, for each player, calculate the expected Pts (equals FGA * average FG%) and actual Pts scored at each location each defender distance 3, take the difference between these two, the more positive the difference is, the more value that player added to team offense from a scoring point of view. 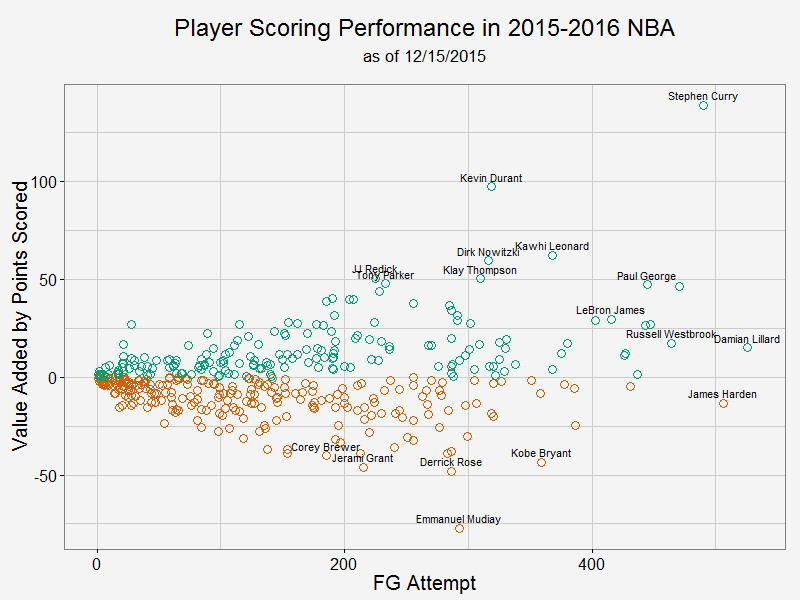 As we can see from this plot, Curry has added the most value to his team while also taken a tremendous amount of shots. In fact, he added almost 5 points per game to Warriors' offense. KD takes less shots, but he is actually more efficient than Curry per shot attempt. Damian Lillard and James Harden take most shots in this season and they are about average. In this analysis, I didn't take free throws into account. As a result, players like James Harden are under-appreciated.
For those who have negative impact to their team, we see Mudiay and Rose leading the way. If you take a look their FG% break down, it is mostly because they couldn't finish contested shots in the paint and open 3 pointers. Notably, Kobe is also in the bottom 5. All right, there you have it. I will put another article on how to construct the shiny app during this holiday season. Until then, have fun comparing your favourite player with the rest! Previously, I plotted all the routes during a 24 hr span by Car2go customers in Austin. While it shows each individual route and its origin and destination, many of them were covered by the last plotted route if they share the same road. As a result, the plot does not show a lot of information (it is colorful though). Today, I modified the code a little bit to uncover the most popular road by Car2go customers. I dropped color = name in geom_path(), but grouped the routes by each car so that routes by different cars are not linked. I added alpha = 0.1 for transparency. This way, the road will show its popularity based on the color transparency, i.e. road with solid color is more popular than those with transparent color. 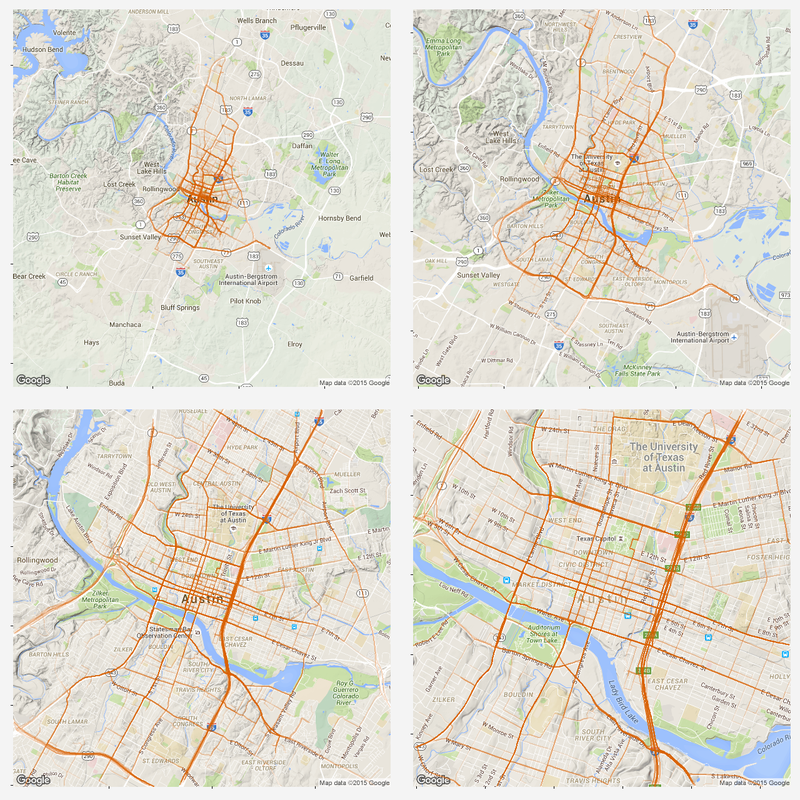 As we can see, MoPac Expy, Interstate 35, Hwy 290 and roads in downtown are most popular. Amongst downtown streets, east and west bound roads (number streets) are more popular than south and north bound roads, as interstate 35 and Lamar Blvd take majority of east-west traffic. Another reason might be that south and north bound roads are narrower and have more stop signs.
As why this color to represent the routes... Once again, all the codes are published here. Comparing total QBR with Passer Rating-Who are the most underrated and overrated passer in NFL12/11/2015 Total Quarterback Rating (Total QBR) is a measure for QB performance created by ESPN in 2011. It was intended to overcome obivous drawbacks of passer rating, which is purely based on passing stats. Total QBR evaluates each play and assigns a value according to many factors (like outcome of the play) including subjective ones, such as how clutch the throw was, how much pressure the passer was under, etc. Passer rating is much simpler, it only measures the 'hard stats': passing yards, TDs, etc. Which rating system is more representative of QB performance is debatable. While total QBR has received a lot of critics (partly because ESPN has not released the model), it is arguably a more valuable measure of the value of a QB (after all, a WR who catches a ball travelling 5 yards in the air and runs 80 yards for a TD should receive more credit than the QB). So the question is how are these two compared with each, and what might be the takeaway from this comparison. Scrape data from ESPN PLAYER columns have different values for same player PLAYER columns have different values for same player The data on ESPN website is different from stat.nba.com or Car2go, which I worked on previously. They are stored on the server and can be extracted rather easily using readHTMLTable(). Note player name values are different in each table. Therefore I made a short string and merge() the two tables into one with by = 'playerShort'. Total QBR vs passer ratingThe data is rbinded to include years from 2006 -2015. Below is a gif loop over the comparison plot for each year. The overall trend is expected: total QBR and passer rating are positively correlated. I plotted the linear regression and 95% confidence interval as well. If we make the prediction of QBR from passer rating based on this curve, this is not too far off. Of course ESPN has more advance stats as input data to find a better regression (basically the QBR model), but passer rating is also robust and much simpler. It is essential for a model to be easy to understand, even sometimes, this means a little accuracy is sacraficed (again, this is debatable here). Without realeasing the actual model makes QBR hard to explain to someone, not to mention the subjective metrics: how clutch is clutch... 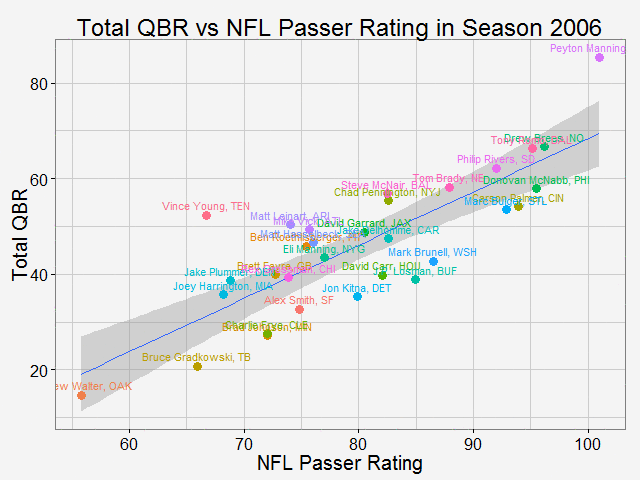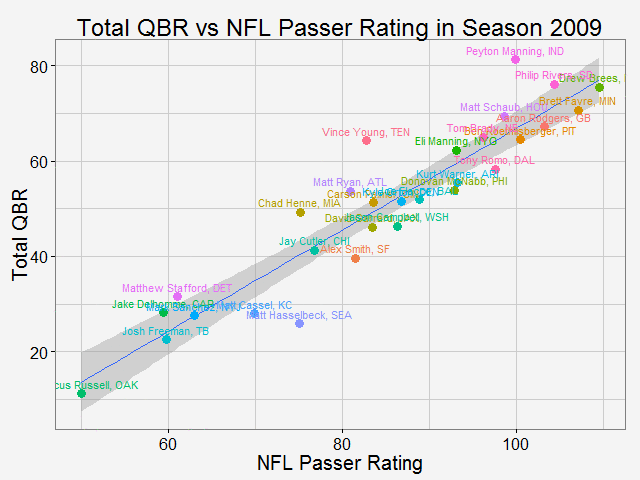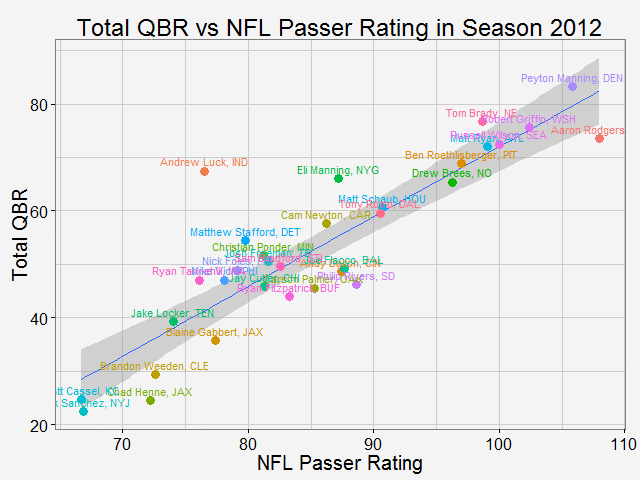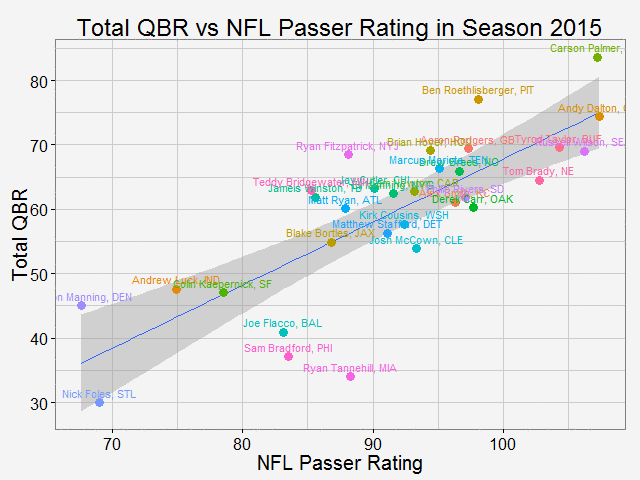 The underrated and overratedNever the less, let's say the 'clutchness' of the world really makes a positive impact to player evaluation and since passer rating fails to capture it, we can make a judgement whether a player is under- or overrated. For example: Ryan Tannehill's passer rating this season is 88.3, which is about average. However, his QBR is only 34 ( voice of Skip Bayless: over the scale of 0 to 100), which is pretty bad. As a result, he is overrated as an average passer. On the flip side, Andrew Luck's passer rating in his rookie season was 76.5, about 10 points below average, but his QBR is 67.4, way above average. So in his rookie season, Andrew Luck was underrated as a below-average passer. In fact, he was very clutch. Next, I plot the top 15 most under- and overrated passers in the past decade. The criterion is the residuals() of the aforementioned regression in each year (QBR may only be compared in single season). This is a very interesting plot, especially when you are very familiar with NFL QB stats and performance in the last decade. For me, I only became a fan since recent years, so bear with me. 1: As good as we think Peyton Manning was from 06-10, he's not getting enough credit 2: Ryan Tannehill is really bad this season, like much-worse-than-we-thought bad. 3: Kevin Kolb was even worse back in 2011 in Arizona. 4: Philip Rivers posted best passer rating in 2008 with 105.5, but he was not as good as many other QBs that year in terms of value added to the team (Charges won AFC west with 8-8 record.) 5: Jay Cutler appeared twice on the underrated passer list, the latest was 2013 season, after which he signed a seven-year deal with the Bears 6: Ryan Fitzpatrick is clutch this year! Enough said. 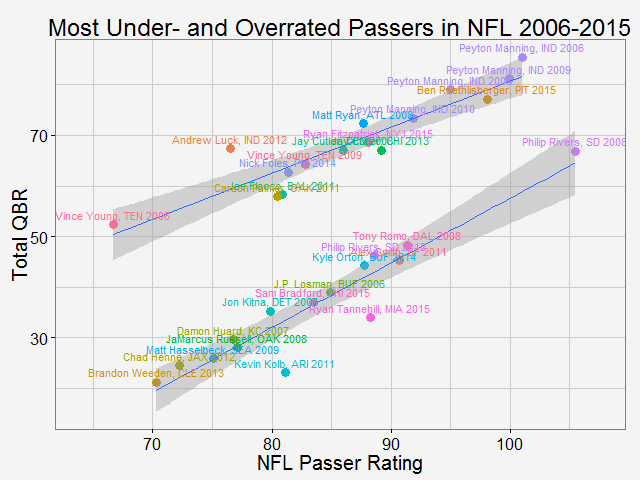 Over the last decade, the average passer rating has increased from 80 to over 90. No doubt NFL is becoming a passing friendly league (We can look at other metrics like increasing QB salary/cap, and the flip side of RB, penalties called to protect QB, average play per game and etc., but this is another article ). Average QBR shoule be 50 (per definition?), but here I am only presenting the QBR averaged over player (I guess more accurately, I should average over per play, but I don't have the data). 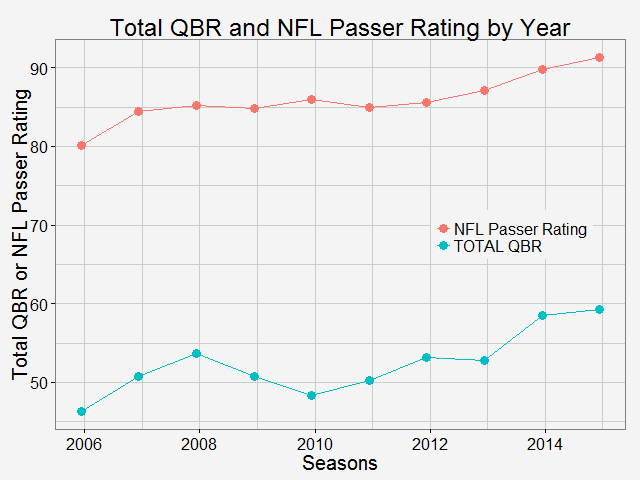 The entire code is published here. I partly used Mr. Todd W. Schneider's theme for my plots.
Identify moved carsFirst, we need to identify whether the car has moved or not. To do this, I removed duplicated rows based on location and only keep those whose location info has changed. Next, I get the rows represent the car first and last shown at that location (this is to get the time stamp of a trip: last shown at location is the start of a trip and first shown at another location if the end of a trip). Find and accurately plot the routeThen I use a for loop to loop through different cars (that have moved) and for each car, I loop through different trips (most likely, a car will have multiple trips). For each trip, I can get the route info from goole map api (library(ggmap) does it). It also gives the distance between each turn. The route info is an approximation to the actual movement of a car. Car2go doesn't supply realtime GPS info when the car is moving, it only records when a customer checks out a trip. However, I think the approximated route is close enough to a real life scenario, which assumes most car2go customers use the service for transportation purpose, other than leisure and recreation activities. 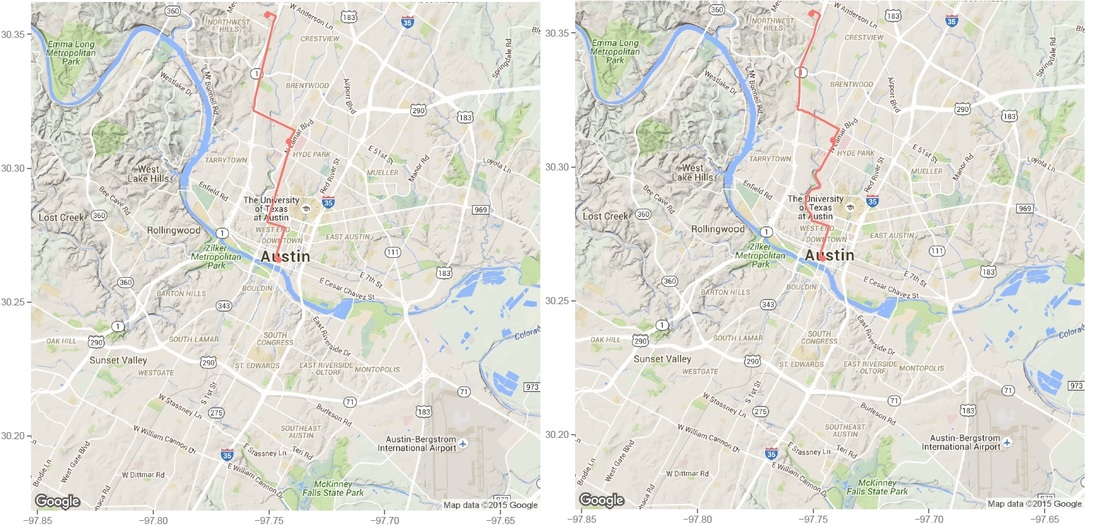 Left: route plotted from turn-by-turn instrctions. Right: same route plotted from detailed polyline from google map api. Left: route plotted from turn-by-turn instrctions. Right: same route plotted from detailed polyline from google map api. Then I was able to plot the route for each car using the route data return by google maps. The result is shown on the left below. While it roughly represents the route on the map, it fails for curvy roads with less turns. The reason is that route(output = 'simple') only gives instruction for each turn, and between each turn, geom_path uses a straight line. In order to solve this problem, I found this article, which converts polyline from goolge map api with route(output = 'all') and outputs (lon, lat) coordinates. Now the path represents the actual route on the road, as shown on the right plot above. All trips during a 24hr spanNext, I plot all the trips happened over Dec 07 13:40 - Dec 08 13:36 (Monday - Tuesday). The covered area is, as expected, similar to the service area of Car2go Austin. 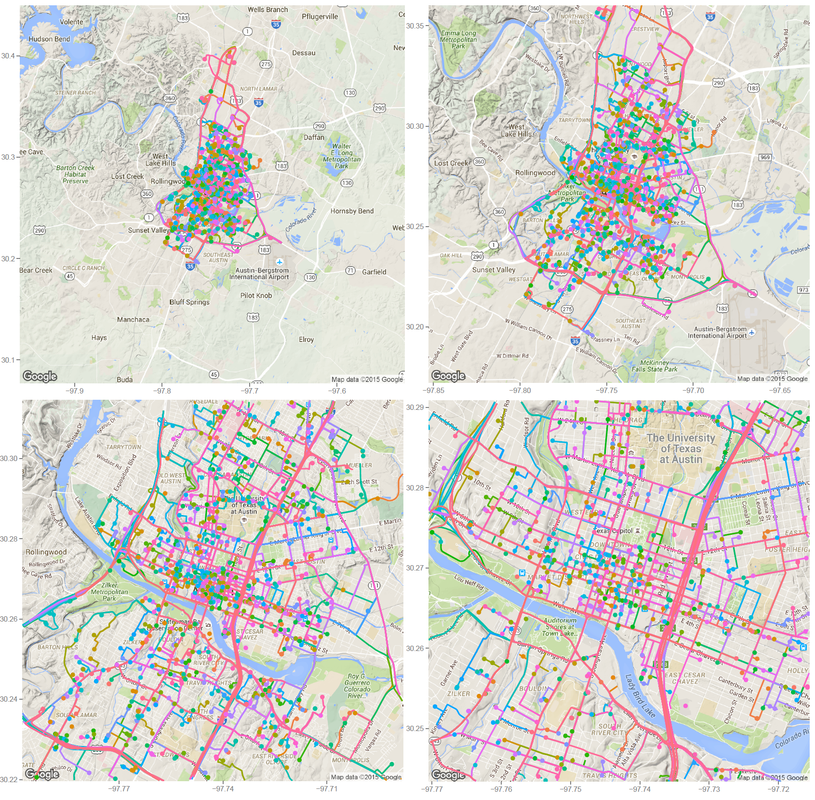 Car2go trips in Austin, TX in 24hrs Suprisingly, no trips took place in UT campus during this period (except very few in north campus). There could be several reasons: 1: limited parking space, 2: students are studying at home for final exams rather than taking classes, so there is significant less population, 2: Car2go is less popular than public transport for students. The actual reason is unknow from this set of data. More data (taken during normal semester time, during weekend when more parking is avalable, etc.) is needed. Update: I just found UT campus is a stop-over area only, therefore, it is not suprising at all. Trip statisticsNext let's take a look at trip statistics. 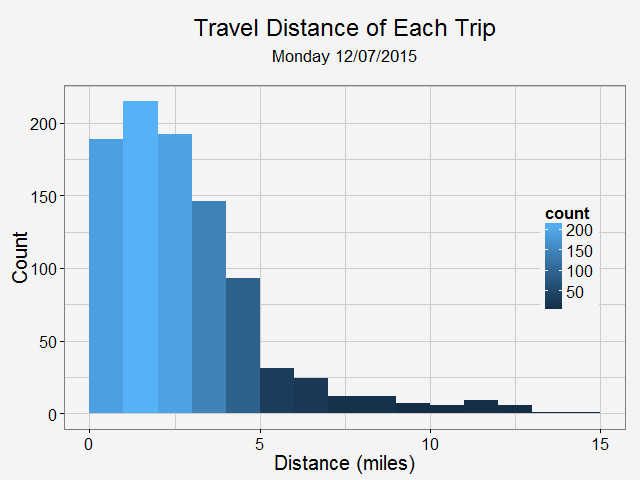 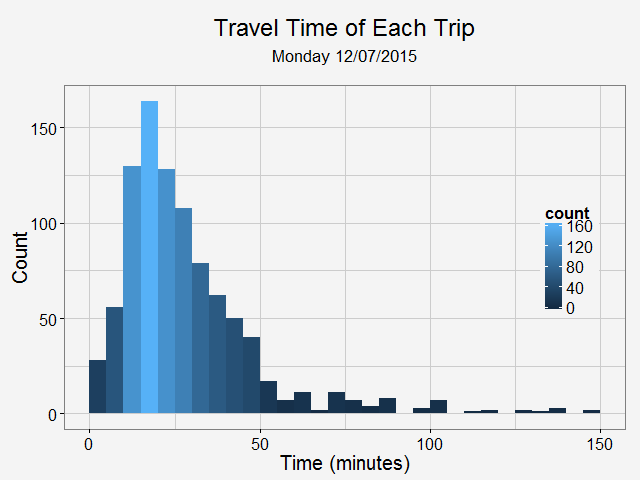 Most trips are less than 5 miles and 50 minutes. Note there are a significant amount of less than 1-mile trips. While some of them are actual trips by customers, the rest could be noise in the data or moveover by Car2go. Now, we can take a look at the starting time of a trip during a day. 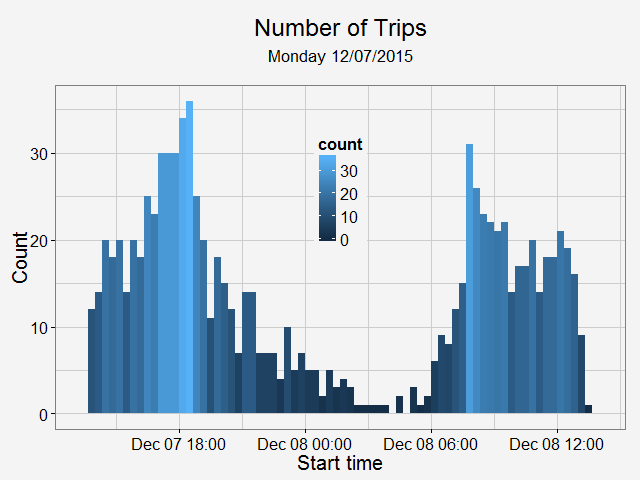 As shown in the above plot, most trips are for commute (~8am and ~6pm) and very few trips took place during midnight.
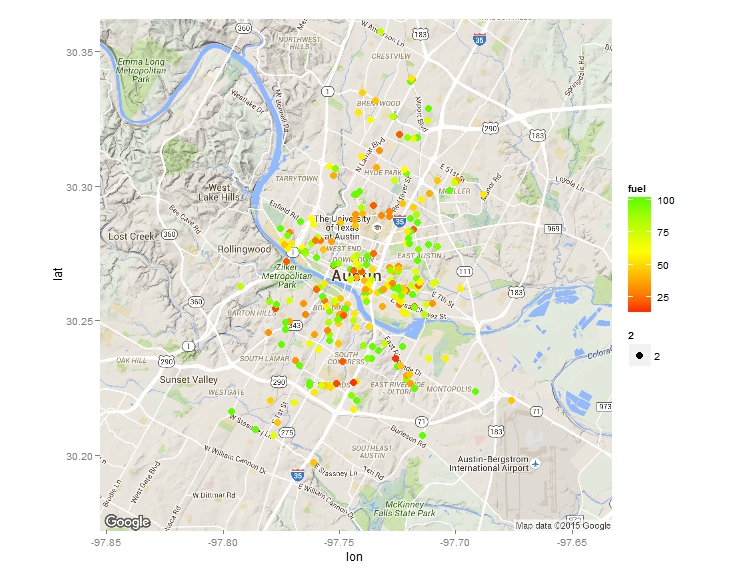 After I published an article on how to scrape advanced shooting data from stat.nba.com, a friend of mine contact me to see whether I may be able to scrape some data from zipcar or car2go’s API. So I looked into it and found it is quite straight forward to do. Here is an example to scrape data from car2go. Car2go is a popular car sharing program in North America and Europe. Here is a little introduction from Wiki if you haven’t about it: The company offers exclusively Smart Fortwo vehicles and features one-way point-to-point rentals. Users are charged by the minute, with hourly and daily rates available. As of May 2015, car2go is the largest carsharing company in the world with over 1,000,000 members. A typical URL looks like this. Anything after json is not needed. After putting it into R (using jsonlite), you will see a list of 1 data frame. However, the column coordinates need special attention as it is also a list. Therefore it is treated differently as other columns, and then they are then 'cbind'ed.  Also note cities with EVs have an attribute of 'charging' while others don't, in order to have a consistent sata structure, I first identify those cities based on length() of the data. Then incert a charging column into those that don't have and assign a value of NA. A for loop can be used to scrape data from different cities, an if statement will automatically identify which data processing code to use. Finally, all the data can be 'rbind'ed and output a csv. It is also quite easy to display all the cars on a map at a give time. Below is one example. I used the ggmap library. Color of each vehicle is to show how much fuel left. The result is the plot at the beginning of the blog. How about the average cleanness of cars in each city? or fuel level? 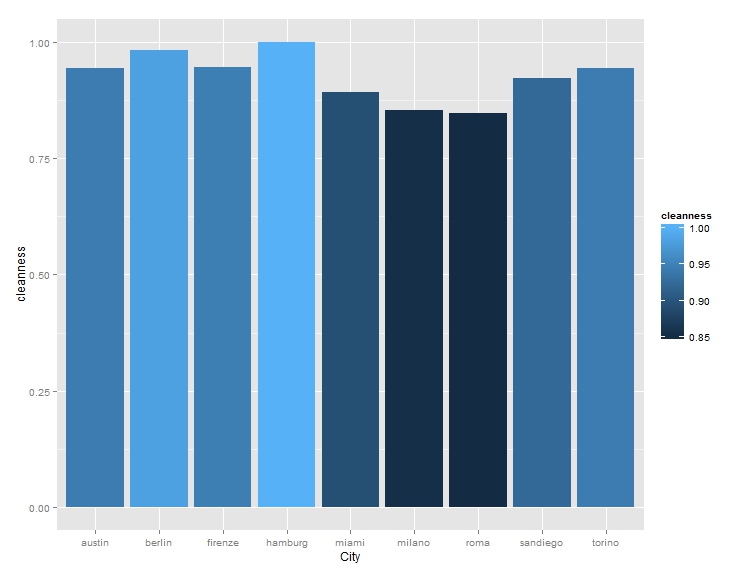 For limited sample size, it seems German cities have the highest car cleanness, Italian cites the lowest, while US cities are in the middle.
The entire code is published here if you are interested. Enjoy! Update: It appears to me that nba.com has removed the access to shot log data as of 02/10/2016. Ever since NBA introduced advanced data to track player on-court movement, there have been a lot of interesting blogs/news articles to show how data could improve the understanding (or destroy your intuition) of the game. Reading them is a lot of fun. Here is one example. The newly introduce metric called KOBE measures how difficult a shot is. A more recent article on http://fivethirtyeight.com/ praises a player to new high using data science (which is arguably more convincing at the first glance). A simple logistic regression is used to predict an outcome (made or not) of a shot based on the shot distance, shot clock remaining and distance to closest defender. Whether the correlation is strong enough to give a reliable prediction is not given. However, the result is somewhat people who have followed NBA would expect. Curry, amongst Durant, Korver and DeAndre Jordan, is the most efficient shooter in NBA. While the regression is quite easy to formulate, getting and cleaning the data is not so straightforward. None of the articles I found online (including the above) gives a direct link to the data, or even the details how to get them from nba.com. Interested in doing some interesting analysis myself, I decided to make such a data frame. Finding the correct url could be a little tricky, as you really need to dig into the website. Here is one very useful resource about how to scrape data from a website. Here I get a list of player ID and the corresponding names. Data from 2014-2015 is collected from each player in that list and then combined into a single cvs file. The code is published here. And if you don't want to run the script but just want to play with the data, I included the cvs file as well. The file size is about 30 MB and has more than 200,000 shot attemps. Enjoy!  |
AuthorA mechanical engineer who also loves data. Archives
January 2018
CategoriesBlogs I enjoy reading |


 RSS Feed
RSS Feed
